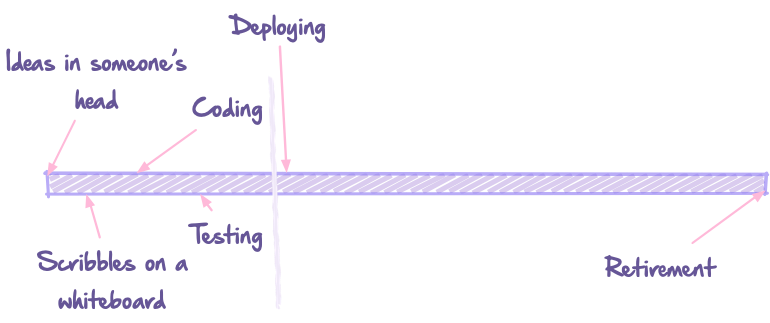
Fixing up a Petster Penguin!

Learn about the adorable Petster Penguin, a later revision of the Catster. Discover its unique features, including a “Go Play” switch and waddling motion. Dive into the internals and find out how to fix its movement problem.